
Unless you’ve been living under a technology rock, you know that Generative AI is the hottest technology to come around in a while. So-called pundits are comparing it to the introduction of the iPhone, which ushered in the mobile wave, or even the World Wide Web (gasp!).
I don’t know what the ultimate impact of Gen AI will be, but I do know it feels like we are currently in a race. A race to figure out how to build Gen AI applications that can take advantage of the groundbreaking power of this technology that we’ve all intuitively understood since we typed that prompt into ChatGPT and got back that mind-blowing response.
Since that moment, I have wanted a quick and easy way to turn my Gen AI ideas into a prototype. And once I have a prototype that looks good, a clear path to turning that into a production application. And knowing the power of streaming and event-driven architectures, I wanted those applications to be event-driven. In other words, I want an easy way to combine the power of streaming with the power of the Large Language Model in a way that is flexible enough to evolve as we learn more about what we can actually accomplish with Gen AI.
And on top of that, I want someone else to take care of the hard parts, so I can just focus on building out my great Gen AI idea.
Given that, you’ll understand why I am super excited to introduce LangStream.
What is LangStream?
LangStream is an open-source project that combines the best of event-based architectures with the latest Gen AI technologies. With LangStream you can build streaming Gen AI applications rapidly. For an example of that, see our talk on Build a Streaming AI Agent using OpenAI, Vercel, and Astra DB in 10 lines of code.
LangStream applications are composed of a series of workers which cover common tasks like calling a vector embedding API from HuggingFace, sending a prompt to OpenAI GPT-4 for a chat response (completion), sinking data into a vector database like Cassandra, or querying a Postgres database to retrieve data to include in the prompt.
Once you’ve built it, you’ll be able to scale it reliably using an event-driven architecture. You declare your Gen AI components and LangStream will automatically deploy it as a streaming application for you. Going from a local development environment to a production environment is as easy as updating and re-running the deploy command with a new target environment.
Prompting LLMs
Before we dive into the details of LangStream, let’s step back and consider the key component of any Gen AI application–the Large Language Model (LLM). Whether the model is from OpenAI, Google, or open source and hosted on Hugging Face, the quality of the LLM response depends on the context you provide in the prompt. The moment of constructing the prompt is key to a Gen AI application. After all, the prompt is the input to the LLM that actually triggers AI to generate something useful, whether that be an answer to a question, a summary of a document, or suggested solution to a problem.
The data that you put into the prompt or the context for the LLM call is critical. The quality of the data you put in dramatically changes the quality of the response you get. This prompt data is usually not new. It’s data you already have stored in databases, caches, or flowing from your application in a users session. In a sense, what you are really doing is building a data pipeline that brings all the data you need for your context to the LLM so you can use it at the moment of prompt construction.
This is exactly how LangStream works. A LangStream application is a collection of data pipelines that work together to make sure that the data needed to construct a high quality prompt is available at the moment you are sending the prompt to the LLM. Since that data can reside in many different places, either at rest or in motion, LangStream includes powerful integrations that allow you to bring your data to the LLM.
Hard things become easy
Many times I’ve talked to people who just want to take a PDF and build a chat bot to talk to it. But this is actually a hard problem even with one PDF. You’ll need to convert it to text, tokenize that text, chunk it, make sure the chunk of tokens match the LLM token limits, pass the text to LLMs for vectorization, determine the best overlap of the chunks, store those vectors in a database. Then make a processing pipeline to understand what the user is saying, similar to the above, tokenize, chunk, LLM, then do a similarity search in the document to find the relevant text but also taking into account the previous messages in the conversation and return that text to an LLM to be able to formulate a response. All without hallucinations and staying on topic. And once you do it with one PDF you’ll want more across hundreds of sources.
The good news is that there are components that exist to do each of these steps for you and LangStream makes it quick and easy to accomplish each step.
Declare and deploy
Let’s take a look at a simple LangStream application. Vector databases are a powerful tool for finding relevant data to include in your LLM prompt using semantic search. However, before you can do a semantic search in a vector database, the data that you want to search needs to be first converted into vectors using an embedding model, such as OpenAI’s text-embedding-ada-002. Here is a LangStream file that defines an application to calculate vector embeddings on a stream of text data:
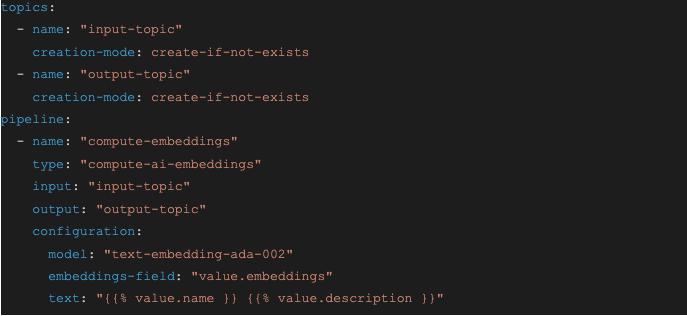
The compute-embeddings agent waits for events in JSON format that contain a name field and a description field. It puts those fields together and sends them to the embeddings model, in this case OpenAI’s text-embedding-ada-002 model, to calculate vectors. It then stores vectors in a new field in the JSON called embeddings. The updated event is sent to the output (output-topic) for further processing. Typically, the event would be written to a vector database.
Of course, for this pipeline to work you would also need to specify configuration information for OpenAI API, which is done in a file like this:

LangStream recognizes that development, test, and production environments are often separate and supports deploying the same application to different instances, which typically represent different environments. It also understands that things like passwords and API keys need to be treated differently so it provides a mechanism for handling secrets.
To deploy the above application to a local development environment is as simple as running this command:
langstream deploy embed -app ./embed/ -i local-dev.yaml -s secrets.yaml
This command sends the application definition to the LangStream planner, which calculates how to realize the application using Kafka topics and Kubernetes pods (more on that later) so you don’t have to worry about configuring infrastructure. You can update the application using the update command, or deploy it to a different environment by specifying a different instance and secret configuration. Because LangStream applications are declared as a collection of YAML files, it is easy to integrate them into a GitOps workflow.
For a more complex example check out the docs to see how LangStream can construct a prompt and call a Large Language Model. One key point when working with the ai-chat-completions agent is the use of prompt logging.You can configure an agent to log the complete prompt it sends to OpenAI along with the response. This makes it easy to tap into the prompting data and read it in real time, for example for quality or abuse monitoring, or store it in a database for later analysis.
LangChain and LlamaIndex
LangStream supports both pre-built and custom agents. Custom agents can import any Python library which can be specified and uploaded along with the application when you deploy it. However, LangStream’s Python runtime environment comes preloaded with the latest versions of popular Gen AI libraries like LangChain and LlamaIndex. It also includes common Python data processing libraries like pandas and Scikit-learn.
Custom agents can take the role of source, processor, or sink in any pipeline, which means that can be the beginning, middle, or end of the pipeline. Given this flexibility and library support, you could convert a prototype you have written using LangChain, for example, into an event-driven Gen AI application using LangStream.
Event-driven and extendable
Why would you want to convert a prototype application to LangStream? Well with LangStream you get an event-driven architecture for your application that has many advantages:
-
Scalability and Performance. As Gen AI applications scale, it is expected they will have to handle massive volumes of data. Asynchronous processing can dramatically improve scalability compared to traditional request-response models.
-
Real-time Processing and Responsiveness. Event driven applications can deal with data as it is generated, not stale, batch-processed data. As Gen AI applications push the boundaries of what is possible, harnessing the power of real time data will be critical.
-
Loose Coupling and Agility. Because components are loosely coupled, they operate independently. This means it is easy to evolve and extend functionality within an event-driven architecture. Given the pace of change in Gen AI, this type of agility is crucial.
-
Fault Tolerance. Events are stored until they are processed so in the event of a failure, processing can pick up where it left off. In the case of a spike in usage, the streaming platform acts as a buffer until the downstream components can catch up.
Granted, event-driven architectures can be more complex for simple applications, but LangStream solves this complexity for Gen AI applications. Without an event-driven architecture GenAI applications are limited by LLMs that can lose context, produce inconsistent answers, and are bounded by their last training data. With this architecture you can unlock techniques like FLARE, chain of thought reasoning, self-consistency, and more to build applications for real-time content generation, dynamic conversational agents, adaptive learning systems, real-time analytics and reports, intelligent monitoring, and more.
Composable and customizable
LangStream application agents operate on event data. Each agent modifies or transforms the data before passing it to the next agent in the pipeline. LangStream comes with several pre-built agents that perform common data, text, and Gen AI processing. The pre-built agents are configuration driven (no code) and fall into the following categories:
-
AI Actions. Examples include computing embedding vectors and or calling chat completion APIs like GPT-4. Chat completion includes prompt templating for prompt engineering.
-
Data Transform. Examples include dropping a field, computing a new value for a field based on existing fields.
-
Text Processors. Examples include extracting text from a PDF file, splitting text into chunks for vectorization, and trimming spaces.
-
Input & Output. Examples include reading files from S3, crawling a website for HTML, reading and writing data to a (vector) database.
AI actions are performed by making API calls to popular hosted services such as OpenAI, Google Vertex AI, and Hugging Face. For vector embeddings, it is also possible to download and run open-source models from Hugging Face.
These pre-built agents make it easy to get started building Gen AI applications with LangStream and we will continue to add more of them. However, there are always special cases where the pre-built agents will not do exactly what you need. For these cases, LangStream supports custom agents written in Python.
You can mix and match pre-built and custom agents in your pipeline to sophisticated data processing pipelines. You can have multiple agents consume data from the same input topic to create parallel pipelines, route events to different pipelines, or have multiple agents send events to a single topic to aggregate results.
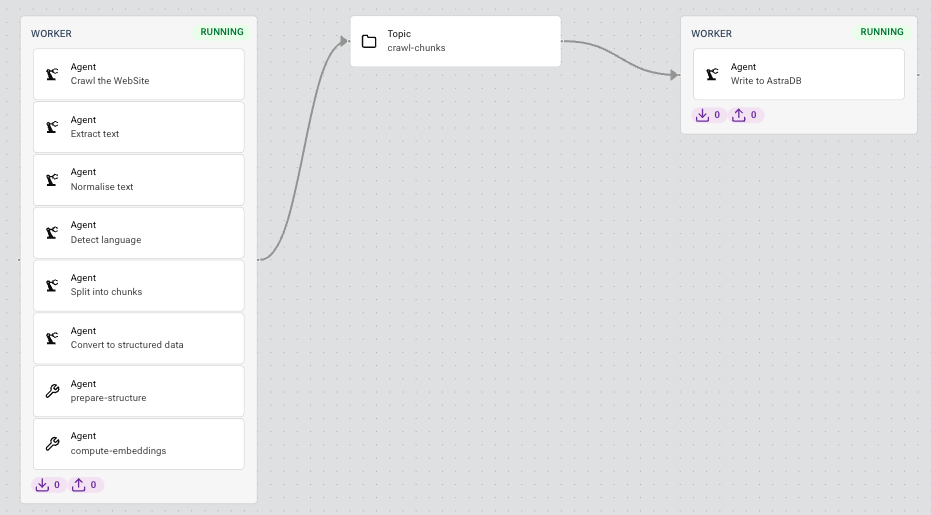
Built on Kubernetes and Kafka
When it comes to building production-ready applications, building on proven technology makes a lot of sense. That’s why LangStream is built on top of proven production infrastructure like Kubernetes and Apache Kafka that has been used for the last decade to build these types of applications.
When you deploy an application, the LangStream planner converts that into a series of Kafka topics and Kubernetes manifests to build the application pipeline—so you don’t have to. You can explicitly define Kafka topics to use in your pipeline if you want to, or you can let LangStream figure that out for you, including any intermediate topics that may be required to make the pipeline flow efficiently.
In addition, Kafka’s rich ecosystem brings you connectors for accessing data in databases, caches, and other messaging systems. This includes popular connectors like Debezium connectors for Change Data Capture (CDC) from databases like Postgres and MySQL so you can build pipelines triggered by change events from your applications.
LangStream also includes a WebSocket gateway. The gateway makes it easy to build applications that leverage LangStream, such as front-end interfaces that run inside the browser. And since these types of applications typically have multiple independent users, the LangStream WebSocket gateway supports user sessions, so that many independent user sessions can connect without a concern.
Observability and open source
One important aspect of observability is the design of the application itself. Applications that have a high level of abstraction hide a lot of the complexity. While that is great for rapid prototyping, it is a challenge in production since we cannot easily get the insight into what the application is doing when it is failing. Application needs to be built with components at the right level of abstraction with proper logs and metrics to allow you to debug the inevitable problems that happen in production.
With LangStream you can build Gen AI applications with the right level of abstraction and with the right amount of logs and metrics so you can figure out what’s going when you need to. LangStream natively supports Prometheus metrics and includes tooling to get easy access to all the Kubernetes logs of the application.
You don’t have to take our word about whether we got these things right in LangStream. LangStream is an open source project so you can easily check it out for yourself. You can find the project on GitHub here. We welcome your feedback and insights to help us improve LangStream. We are also inviting contributors to help us build LangStream.
To make it easier for you to get started with LangStream, we have created a Visual Studio code extension for LangStream. With the extension you can interact with LangStream applications directly from your IDE, including snippet completion while building a pipeline. You can find it in the marketplace here.
Wrapping up
That is a quick tour of LangStream.
LangStream is the easiest way to build Gen AI applications. You can declare your applications in a low- or even no-code way and let LangStream figure out how to turn that into an event-driven application. LangStream provides support for popular Gen AI technologies from OpenAI, Google, and Hugging Face. You can write custom agents in Python using the most popular Gen AI libraries like LangChain and LlamaIndex. Because your LangStream application is event driven, it inherits the scalability, robustness, and extensibility of all applications that use that architecture.
LangStream is built on production-proven open source projects like Kubernetes and Kafka. It provides the right level of abstraction to create Gen AI applications with the right level of observability so they can be managed in production. LangStream itself is open source and we look forward to engaging with users to help us improve and grow it to become the best way to build Gen AI applications.
Feel free to reach out to us on our Slack channel.

Chris Bartholomew